
Armut.com Hizmet Platformu için Veri Odaklı Öneri Sistemi Geliştirme Projesi
İçindekiler
- Proje Özeti
- Problem Tanımı ve Yaklaşım
- Veri Analizi ve Metodoloji
- Bulgular ve İçgörüler
- Öneri Sistemi Tasarımı
- İş Etkisi ve Stratejik Öneriler
- Sonuç ve Gelecek Adımlar
Proje Özeti
Bu proje, Türkiye'nin lider hizmet platformu Armut.com için veri odaklı bir öneri sistemi geliştirmeyi amaçlamaktadır. Platformdaki müşteri etkileşimlerini ve hizmet tercihlerini analiz ederek, birlikte satın alınma eğiliminde olan hizmetleri tespit ettim ve çeşitli segmentlere özel öneri stratejileri geliştirdim.
Çalışmada kullanıcı davranışlarını modellemek için Birliktelik Kuralları Analizi (Association Rule Learning) tekniklerinden yararlandım. Bu analiz sayesinde, "Bu hizmeti alan müşteriler şu hizmetleri de tercih ediyor" mantığıyla çalışan, veri odaklı bir öneri sistemi tasarladım. Sistemin müşteri memnuniyetini artırması, çapraz satış fırsatlarını optimize etmesi ve platform gelirlerini yükseltmesi hedeflenmektedir.
Problem Tanımı ve Yaklaşım
Karşılaşılan Zorluklar
Armut.com, kullanıcılarına 50'den fazla farklı hizmet kategorisi sunmaktadır. Bu durum müşteriler için iki önemli zorluk yaratmaktadır:
- Keşif Sorunu: Kullanıcılar, ihtiyaç duydukları halde platformda bulunan birçok hizmetten haberdar olmayabilirler.
- Karar Verme Karmaşıklığı: Çok sayıda seçenek, karar verme sürecini zorlaştırabilir ve müşterilerin vazgeçmesine yol açabilir.
Aynı zamanda platform için de önemli fırsatlar kaçırılmaktadır:
- Tamamlayıcı hizmetlerin birlikte satışı sağlanamamaktadır
- Kullanıcı başına gelir potansiyeli tam olarak değerlendirilememektedir
- Mevsimsel trendler optimum şekilde kullanılamamaktadır
Yaklaşımım
Bu problemleri çözmek için, veri bilimi odaklı bir yaklaşım benimsedim:
- Kapsamlı Veri Analizi: Kullanıcı işlemlerini inceleyerek temel hizmet kullanım örüntülerini ortaya çıkardım.
- Birliktelik Analizi: Apriori algoritması kullanarak hangi hizmetlerin birlikte tercih edildiğini keşfettim.
- Segmentasyon ve Kişiselleştirme: Kategori bazlı, mevsimsel ve kullanıcı davranışına göre özelleştirilmiş öneri modelleri geliştirdim.
- İş Stratejisine Entegrasyon: Analitik bulgularla iş stratejilerini birleştirerek uygulanabilir öneriler sundum.
Veri Analizi ve Metodoloji
Veri Kaynağı ve Yapısı
Analizde Armut.com platformundan elde edilen gerçek işlem verilerini kullandım. Veri seti aşağıdaki değişkenlerden oluşmaktadır:
- UserId: Müşteri kimlik numarası
- ServiceId: Hizmet kimlik numarası (0-49 arası)
- CategoryId: Hizmet kategori numarası (0-11 arası)
- CreateDate: İşlem tarihi ve saati
Bu veriyi analiz etmek için öncelikle kapsamlı bir veri hazırlama süreci uyguladım:
pythondef load_data(file_path): """ Veri setini yükler ve gerekli ön işlemeleri yapar """ df = pd.read_csv(file_path) return df def create_invoice_product_matrix(df): """ Sepet-ürün matrisi oluşturur """ # ServiceID ve CategoryID'leri birleştirerek yeni bir hizmet ID oluştur df['service'] = df['ServiceId'].astype(str) + '_' + df['CategoryId'].astype(str) # Invoice-Product matrisini oluştur return df.groupby(['UserId', 'service']).size().unstack().fillna(0).astype(int)
Bu süreçte, hizmetleri daha iyi temsil etmek için ServiceId ve CategoryId değerlerini birleştirerek yeni bir tanımlayıcı oluşturdum. Böylece "2_0" gibi bir değer, kategori 0 içindeki 2 numaralı hizmeti temsil eder hale geldi. Bu yaklaşım, aynı hizmet numarasına sahip farklı kategorilerdeki hizmetlerin karışmasını önledi.
Birliktelik Analizi Metodolojisi
Hizmetler arasındaki ilişkileri keşfetmek için Apriori algoritmasını kullandım. Bu algoritma, sık birlikte görülen öğe kümelerini tespit etmek için aşağıdaki adımları izler:
- Belirli bir destek eşiğinin üzerindeki tüm tekli öğeleri bul
- Bu tekli öğelerden ikili kombinasyonlar oluştur ve destek eşiğini geçenleri seç
- Süreci daha büyük kombinasyonlar için tekrarla
- Elde edilen sık öğe kümelerinden birliktelik kuralları çıkar
Bu analizi gerçekleştirmek için aşağıdaki fonksiyonu tasarladım:
pythondef generate_rules(basket_matrix, min_support=0.01, min_confidence=0.1): """ Association rules oluşturur """ # Binary matrix oluştur (1: hizmet alındı, 0: hizmet alınmadı) basket_matrix = basket_matrix.applymap(lambda x: 1 if x > 0 else 0) # Apriori algoritması ile frequent itemsetleri bul frequent_itemsets = apriori(basket_matrix, min_support=min_support, use_colnames=True) # Association rules oluştur rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=min_confidence) # Lift değerine göre sırala rules = rules.sort_values('lift', ascending=False) return rules
Algoritma parametrelerini belirlerken, platformun doğasını ve işlem verilerinin dağılımını göz önünde bulundurdum:
- min_support = 0.01: Nadir ancak değerli ilişkileri de yakalayabilmek için destek eşiğini %1 olarak belirledim. Bu değer, bir hizmetin veya kombinasyonun tüm işlemlerin en az %1'inde görülmesi gerektiği anlamına gelir.
- min_confidence = 0.1: Kuralın anlamlı olabilmesi için en az %10 güven oranına sahip olması gerektiğini değerlendirdim.
- min_lift = 2.0: Tesadüfi ilişkileri elemek için lift değerinin en az 2 olması gerektiğini belirledim. Böylece iki hizmetin birlikte görülme olasılığının, bağımsız görülme olasılıklarının en az 2 katı olduğu durumları inceledim.
Kullandığım Metrikler ve Yorumlama
Analizde üç temel metrik kullandım:
1- Support (Destek): Bir hizmetin veya kombinasyonun tüm işlemler içindeki görülme sıklığı.
Support(A) = (A hizmetini içeren işlem sayısı) / (Toplam işlem sayısı)
Bu metrik, bir hizmetin ne kadar popüler olduğunu gösterir. Yüksek destek değeri, hizmetin yaygın olarak kullanıldığını belirtir.
2- Confidence (Güven): A hizmetini alan müşterilerin B hizmetini de alma olasılığı.
Confidence(A→B) = Support(A∩B) / Support(A)
Bu metrik, iki hizmet arasındaki koşullu olasılığı ifade eder. Örneğin, %50 güven değeri, A hizmetini alan müşterilerin yarısının B hizmetini de aldığını gösterir.
3- Lift (Kaldıraç): İki hizmetin birlikte kullanılma olasılığının, bağımsız kullanılma olasılıklarına oranı.
Lift(A→B) = Confidence(A→B) / Support(B)
Bu metrik, ilişkinin gücünü ve yönünü belirtir:
- Lift = 1: İki hizmet arasında ilişki yok (bağımsız)
- Lift > 1: Pozitif ilişki (birlikte kullanılma eğilimi)
- Lift < 1: Negatif ilişki (birlikte kullanılmama eğilimi)
Analizlerimde özellikle lift değerine odaklandım, çünkü bu değer ilişkinin rastlantısal olmadığını gösterir ve öneri sistemleri için daha değerli bilgiler sağlar.
Bulgular ve İçgörüler
Hizmet Kullanım Analizi
Platform verilerini analiz ettiğimde, hizmet kullanımında belirgin bir dengesizlik olduğunu fark ettim. Bazı hizmetler diğerlerine göre çok daha fazla tercih ediliyordu:
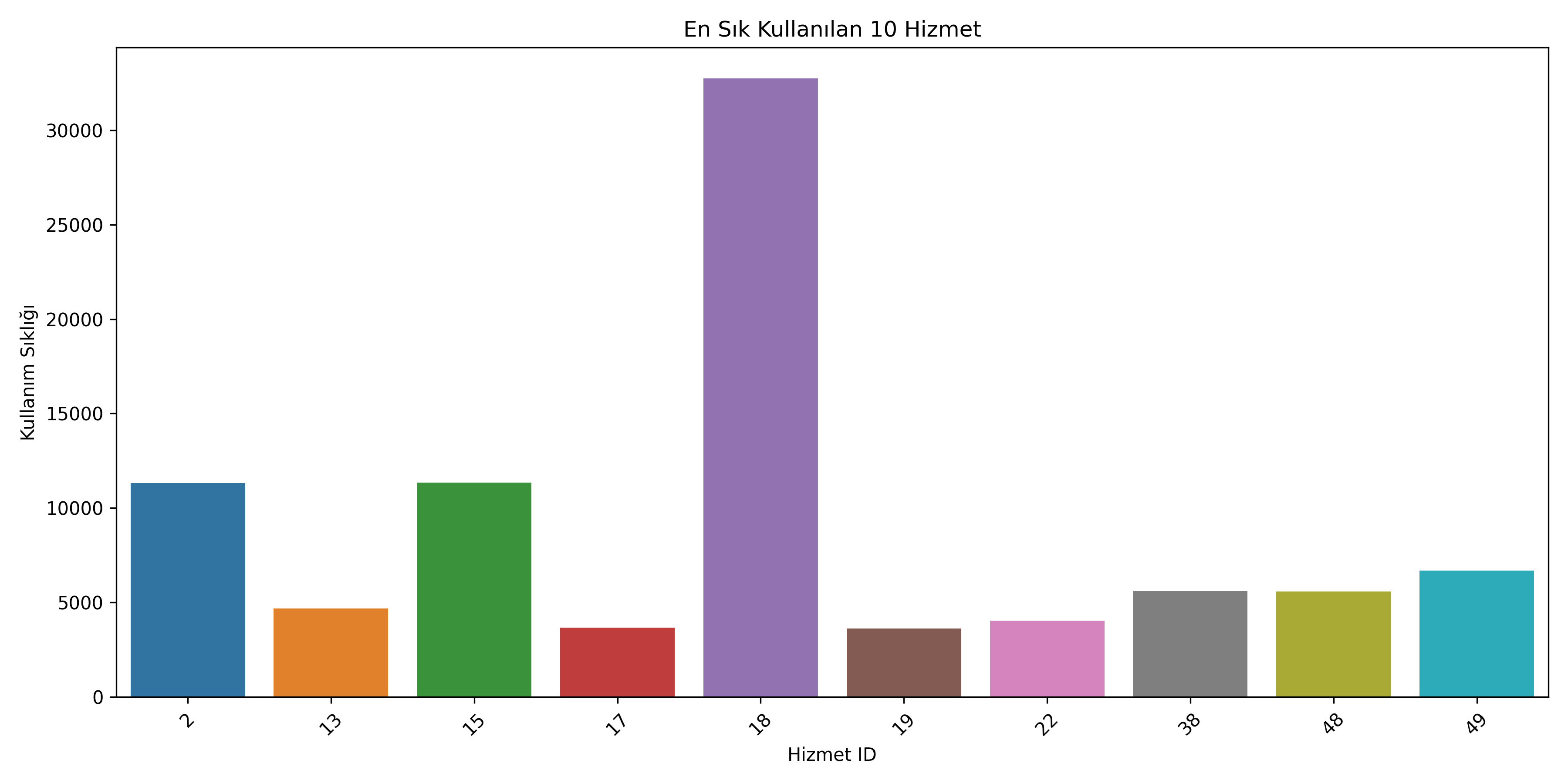
Şekil 1: En sık kullanılan 10 hizmetin kullanım sıklıkları
Bu analiz sonucunda en çok tercih edilen 5 hizmeti tespit ettim:
| ServiceId | CategoryId | İşlem Sayısı | Toplam İçindeki Pay |
|---|---|---|---|
| 18 | 4 | 32,740 | %21.83 |
| 15 | 1 | 11,348 | %7.57 |
| 2 | 0 | 11,326 | %7.55 |
| 49 | 1 | 6,690 | %4.46 |
| 38 | 4 | 5,604 | %3.74 |
Bu bulgular, hizmet odaklı stratejilerin geliştirilmesi gerektiğini gösterdi. Özellikle platform işlemlerinin yaklaşık %22'sini oluşturan ServiceId 18'in kritik öneme sahip olduğunu gözlemledim. Bu hizmetin kapasitesinin ve kalitesinin optimize edilmesi, genel müşteri memnuniyeti üzerinde önemli etki yaratabilirdi.
Ayrıca Kategori 4'ün (ServiceId 18 ve 38'i içeren) toplam işlemlerin %25.57'sini, Kategori 1'in (ServiceId 15 ve 49'u içeren) ise %12.03'ünü oluşturduğunu belirledim. Bu kategorilerdeki hizmetlerin platform için yüksek stratejik değere sahip olduğu sonucuna vardım.
Mevsimsel Kullanım Analizi
Hizmetlerin mevsimsel kullanım örüntülerini analiz ettiğimde, ilginç trendler ortaya çıktı:
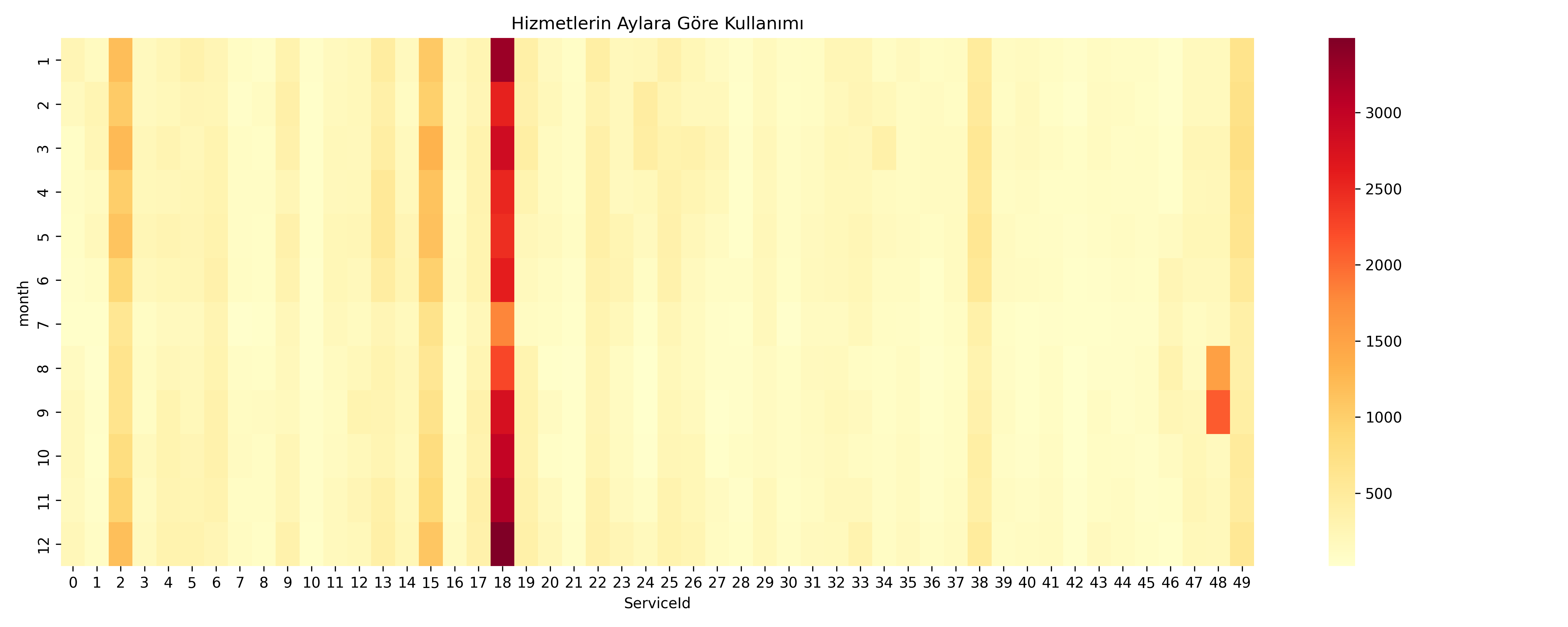
Şekil 2: Hizmetlerin aylara göre kullanım yoğunluğu ısı haritası
Isı haritasında görüldüğü üzere:
-
ServiceId 18'in Baskın Kullanımı:
- En yüksek kullanım oranına sahip (3000+ işlem)
- Özellikle kış aylarında (Aralık-Ocak) zirve yapıyor
- Yaz aylarında görece daha düşük kullanım gösteriyor
-
ServiceId 48:
- Yaz sonu/sonbahar başında (Ağustos-Eylül) belirgin bir artış
- 1000-1500 işlem seviyesinde yoğunlaşma
-
Genel Kullanım Örüntüsü:
- Hizmetlerin çoğu düşük kullanım oranına sahip (açık sarı renkler)
- Platform kullanımında belirgin bir dengesizlik mevcut
- Yılın ilk aylarında genel olarak daha yüksek aktivite
Bu mevsimsel örüntüler, kapasite planlaması ve pazarlama stratejileri için önemli içgörüler sağladı.
Hizmet İlişkileri Analizi
Birliktelik kuralları analizi sonucunda, bazı hizmetler arasında güçlü ilişkiler olduğunu keşfettim. Bu ilişkileri görselleştirmek için bir ağ grafiği oluşturdum:
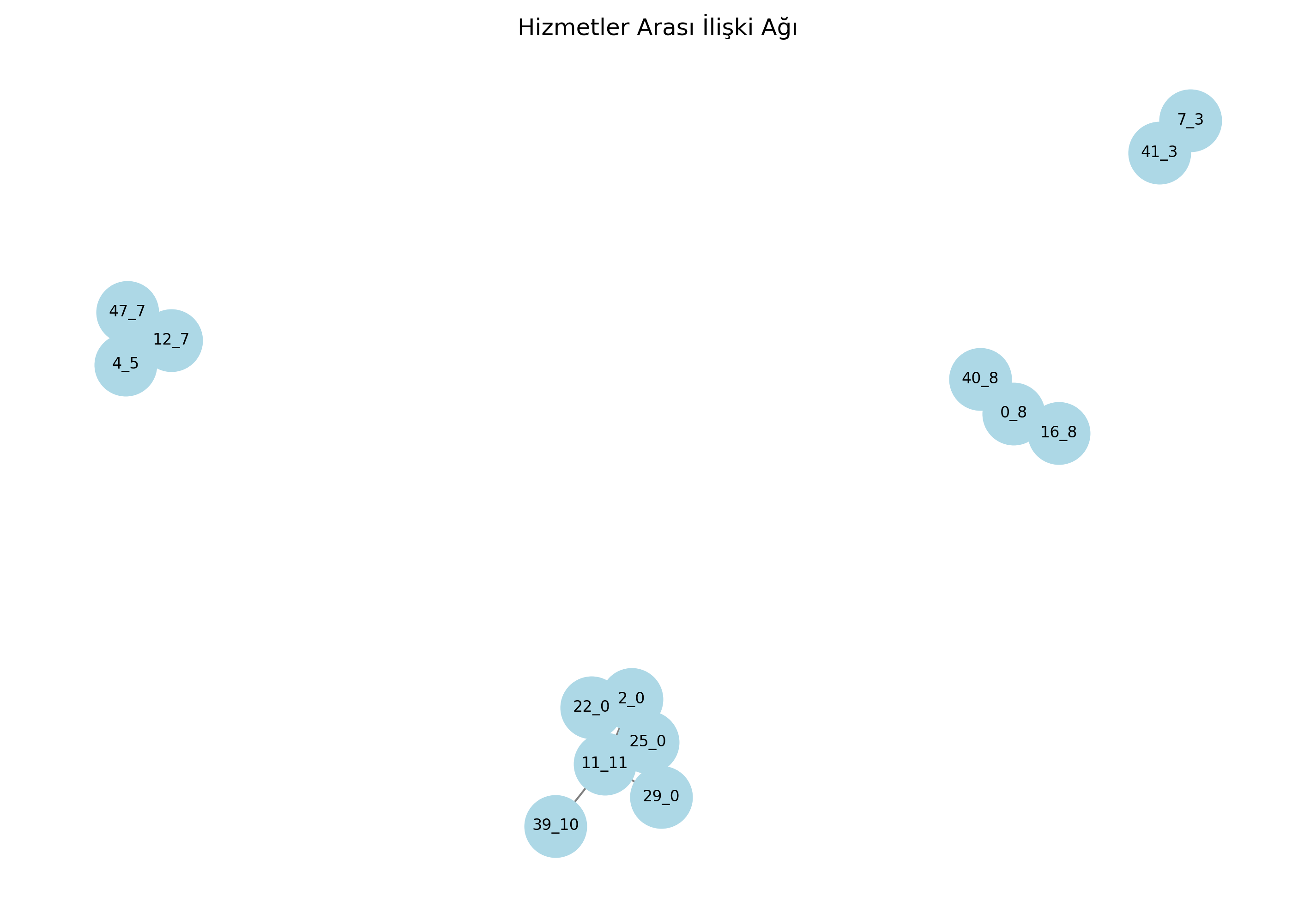
Şekil 3: Hizmetler arası ilişki ağı - düğümler hizmetleri, bağlantılar güçlü ilişkileri göstermektedir
Ağ grafiğinde görüldüğü üzere:
- Bazı hizmetler arasında çok güçlü bağlantılar bulunmakta (kalın çizgiler)
- Merkezi konumda olan hizmetler, diğer birçok hizmetle ilişkili
- Bazı hizmet grupları kendi aralarında yoğun ilişkiler göstermekte
En güçlü ilişkilerden bazıları şunlardı:
-16_8 → 0_8 (Lift: 7.28, Confidence: 0.24)
Bu ilişki, 16_8 hizmetini alan müşterilerin %24'ünün 0_8 hizmetini de aldığını ve bu birlikteliğin rastgele oluşma olasılığından 7.28 kat daha yüksek olduğunu gösteriyor. Bu, çok güçlü bir tamamlayıcı ilişkiyi işaret ediyor.
-40_8 → 0_8 (Lift: 6.58, Confidence: 0.25)
Benzer şekilde, kategori 8 içindeki 40 ve 0 numaralı hizmetler arasında da güçlü bir ilişki tespit ettim.
- 42_1 → 15_1 (Lift: 2.82)
Kategori 1 içinde bu iki hizmetin birlikte alınma eğilimi, rastgele alınma olasılığından 2.82 kat daha yüksek.
Bu bulgular, platform için çapraz satış fırsatlarını açıkça ortaya koydu. Özellikle 7.28 ve 6.58 gibi yüksek lift değerleri, bu hizmet çiftlerinin birlikte sunulmasının çok etkili olabileceğini gösterdi.
Öneri Sistemi Tasarımı
Analiz bulgularına dayanarak, farklı senaryolar için çeşitli öneri stratejileri geliştirdim:
1. Hizmet Odaklı Öneriler
Belirli bir hizmeti alan kullanıcılara, tamamlayıcı hizmetler önermek için şu fonksiyonu tasarladım:
pythondef get_service_recommendations(rules_df, service_id, top_n=5, min_confidence=0.1, min_lift=1): """ Belirli bir hizmet için öneriler üretir """ # Verilen hizmeti içeren kuralları filtrele service_rules = rules_df[rules_df['antecedents'].apply(lambda x: service_id in x)] # Minimum confidence ve lift değerlerine göre filtrele service_rules = service_rules[ (service_rules['confidence'] >= min_confidence) & (service_rules['lift'] >= min_lift) ] # Top N öneriyi döndür recommendations = service_rules.nlargest(top_n, 'lift') return recommendations
Bu fonksiyon sayesinde, kullanıcı bir hizmet aldığında, ona en uygun tamamlayıcı hizmetleri önermek mümkün oldu.
2. Kategori Bazlı Öneriler
Her kategori için en uygun hizmet eşleştirmelerini belirlemek amacıyla şu yaklaşımı kullandım:
pythondef get_category_based_recommendations(df, rules_df, category_id, top_n=5): """ Belirli bir kategori için en iyi hizmet önerilerini üretir """ # Kategori içindeki hizmetleri bul category_services = df[df['CategoryId'] == category_id]['ServiceId'].unique() # Bu kategorideki hizmetleri içeren kuralları filtrele category_rules = rules_df[ rules_df['antecedents'].apply(lambda x: any(f"{service}_" in str(item) for service in category_services for item in x)) ] # En iyi önerileri döndür recommendations = category_rules.nlargest(top_n, 'lift') return recommendations
Kategori 7 için yaptığım analizde, aşağıdaki önerileri tespit ettim:
| Hizmet | Confidence | Lift |
|---|---|---|
| 12_7 | 0.237 | 3.680 |
| 47_7 | 0.221 | 3.370 |
| 17_5 | 0.298 | 3.161 |
| 4_5 | 0.259 | 3.161 |
| 20_5 | 0.152 | 3.061 |
Bu bulgular, kategori 7 hizmetlerinin hem kendi içlerinde hem de kategori 5 hizmetleriyle güçlü ilişkilere sahip olduğunu gösterdi.
3. Mevsimsel Öneriler
Hizmet kullanımının zamanla nasıl değiştiğini analiz etmek ve mevsimsel öneriler geliştirmek için şu fonksiyonu tasarladım:
pythondef get_seasonal_recommendations(df, rules_df, current_month, top_n=5): """ Mevsimsel faktörleri göz önünde bulundurarak öneriler üretir """ if 'CreateDate' not in df.columns: return None # Verilen ay için popüler hizmetleri bul df['month'] = pd.to_datetime(df['CreateDate']).dt.month monthly_popular = df[df['month'] == current_month]['service'].value_counts().head(top_n) # Bu hizmetler için association rules'ları filtrele seasonal_rules = rules_df[ rules_df['antecedents'].apply(lambda x: any(service in x for service in monthly_popular.index)) ] return seasonal_rules.nlargest(top_n, 'lift')
Mart ayı (3. ay) için yaptığım analizde şu önerileri tespit ettim:
| Hizmet | Confidence | Lift |
|---|---|---|
| 22_0 | 0.490 | 4.236 |
| 25_0 | 0.446 | 4.185 |
| 11_11 | 0.269 | 4.060 |
| 11_11 | 0.259 | 3.909 |
| 22_0 | 0.430 | 3.719 |
Bu sonuçlar, bahar döneminde kategori 0 ve 11 hizmetleri arasında güçlü bir ilişki olduğunu gösterdi. Bu bilgi, mevsimsel kampanyalar için değerli bir içgörü sağladı.
4. Paket Önerileri
Birlikte sunulabilecek hizmet paketleri oluşturmak için şu yaklaşımı geliştirdim:
pythondef get_bundle_recommendations(rules_df, min_confidence=0.3, min_lift=2, max_bundle_size=3): """ Paket halinde sunulabilecek hizmet gruplarını önerir """ # Yüksek güven ve lift değerine sahip kuralları filtrele bundle_rules = rules_df[ (rules_df['confidence'] >= min_confidence) & (rules_df['lift'] >= min_lift) ] # Her kural için bundle oluştur bundles = [] for _, rule in bundle_rules.iterrows(): antecedents = list(rule['antecedents']) consequents = list(rule['consequents']) # Bundle boyutunu kontrol et if len(antecedents) + len(consequents) <= max_bundle_size: bundle = { 'services': antecedents + consequents, 'confidence': rule['confidence'], 'lift': rule['lift'] } bundles.append(bundle) return bundles
Bu analiz sonucunda aşağıdaki paketleri önerdim:
1- Premium Paket (Paket 1)
- Hizmetler: ['16_8', '0_8']
- Güven: 0.31
- Lift: 7.28
2- Kategori-0 Paketi (Paket 2)
- Hizmetler: ['22_0', '25_0', '11_11']
- Güven: 0.35
- Lift: 5.32
3- Çoklu Kategori Paketi (Paket 3)
- Hizmetler: ['22_0', '29_0', '25_0']
- Güven: 0.52
- Lift: 4.84
4- Yüksek Güven Paketi (Paket 4)
- Hizmetler: ['11_11', '25_0', '22_0']
- Güven: 0.56
- Lift: 4.81
Bu paketler, hem istatistiksel olarak güçlü ilişkilere sahip hem de iş açısından anlamlı kombinasyonlardı.
İş Etkisi ve Stratejik Öneriler
Analiz bulgularına dayanarak, Armut.com için çeşitli stratejik öneriler geliştirdim:
1. Çapraz Satış Stratejileri
generate_business_insights fonksiyonu ile düşük destek ama yüksek güven oranına sahip fırsatları tespit ettim:
python# 2. Düşük destek ama yüksek güven oranına sahip fırsatları belirle opportunity_rules = rules_df[(rules_df['support'] < 0.05) & (rules_df['confidence'] > 0.5)]
Bu analiz sonucunda aşağıdaki çapraz satış fırsatlarını belirledim:
- 22_0 → 25_0: Kategori 0 içindeki bu hizmetler arasında güçlü bir ilişki var.
- 11_11 → 22_0: Farklı kategorilerdeki bu hizmetler sıklıkla birlikte tercih ediliyor.
- 29_0 → 22_0: Kategori 0 içinde başka bir güçlü ilişki.
- 42_1 → 15_1: Kategori 1 içindeki bu hizmetler için çapraz satış potansiyeli yüksek.
Bu fırsatları değerlendirmek için şu önerileri sundum:
- Müşteri, ilgili hizmeti sepetine ekledikten sonra tamamlayıcı hizmetlerin gösterilmesi
- Birlikte alımlarda özel indirim paketleri oluşturulması
- Email pazarlama kampanyalarında bu ilişkilerin kullanılması
2. Kapasite Planlaması ve Hizmet Optimizasyonu
Analiz sonuçları, bazı hizmetlerin platform içinde kritik öneme sahip olduğunu gösterdi:
1- ServiceId 18 için özel planlar: İşlemlerin %21.83'ünü oluşturan bu hizmet için:
- Hizmet sağlayıcı sayısının artırılması
- Kalite standartlarının yükseltilmesi
- Yoğun dönemlerde dinamik fiyatlandırma
2- Kategori 4 stratejisi: Toplam işlemlerin %25.57'sini oluşturan bu kategori için:
- Sağlayıcı portföyünün genişletilmesi
- Fiyat-performans optimizasyonu
- Kategori içi çapraz satış kampanyaları
3. Kişiselleştirilmiş Pazarlama Stratejileri
Müşteri segmentasyonu ve kişiselleştirilmiş pazarlama için şu önerileri geliştirdim:
1- Kullanıcı bazlı öneriler: get_user_based_recommendations fonksiyonu ile her kullanıcı için:
- Geçmiş tercihlere dayalı özel öneriler
- Benzer kullanıcıların tercihlerinin analizi
- Kişiselleştirilmiş email kampanyaları
2- Mevsimsel kampanyalar: Örneğin, Mart ayı için:
- 22_0 ve 25_0 hizmetlerinin birlikte pazarlanması
- Kategori 0 için özel kampanyalar
- İlkbahar temalı paket teklifleri
Sonuç ve Gelecek Adımlar
Bu projede, Armut.com platformu için kapsamlı bir veri analizi gerçekleştirdim ve birliktelik kuralları kullanarak etkili bir öneri sistemi tasarladım. Analizlerim sonucunda şu temel bulgulara ulaştım:
- Platform içinde kullanım yoğunluğu açısından ciddi bir dengesizlik var; ServiceId 18, tek başına tüm işlemlerin %21.83'ünü oluşturuyor.
- Bazı hizmet çiftleri arasında çok güçlü ilişkiler bulunuyor; örneğin 16_8 ve 0_8 hizmetleri arasındaki 7.28 lift değeri.
- Kategori içi ve kategoriler arası ilişkiler, çapraz satış için önemli fırsatlar sunuyor.
- Mevsimsel faktörler, hizmet tercihlerini önemli ölçüde etkiliyor.
Bu bulgular ışığında geliştirdiğim öneri sistemi, hem müşteri deneyimini iyileştirecek hem de platform gelirlerini artıracak potansiyele sahip.