
Amazon Ürün Yorumları Sentiment Analizi Projesi
📊 Proje Özeti
Bu proje, Amazon'daki perde ürünlerine ait müşteri yorumlarını derinlemesine analiz ederek müşteri memnuniyetini ölçen ve ürün geliştirme süreçlerine yön veren kapsamlı bir veri analizi çalışmasıdır. Doğal dil işleme (NLP) ve makine öğrenmesi teknikleri kullanılarak, müşteri yorumlarından anlamlı içgörüler elde edilmiş, ürün kalitesi ve müşteri deneyimini iyileştirmek için somut öneriler geliştirilmiştir.
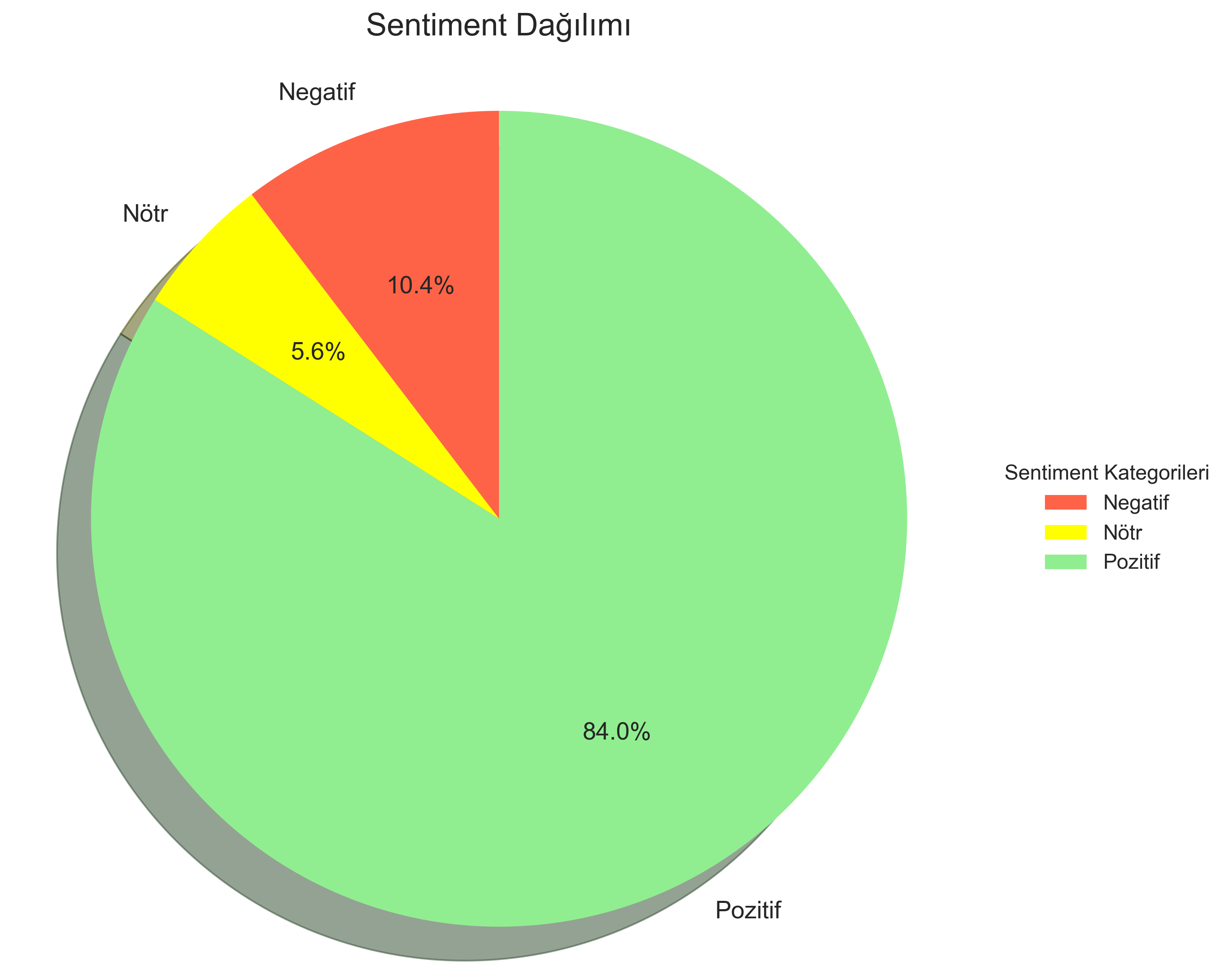
Şekil 1: Amazon perde ürünleri yorumlarının sentiment dağılımı. Pozitif yorumlar (%84.01) yeşil, nötr yorumlar (%5.61) sarı ve negatif yorumlar (%10.37) kırmızı ile gösterilmiştir.
🎯 Projenin Amacı ve Oluşturulma Süreci
Bu proje, e-ticaret sektöründe karşılaşılan önemli bir soruna çözüm bulmak amacıyla geliştirilmiştir: "Müşteri yorumlarından nasıl değer yaratılabilir?". Projeyi oluştururken şu temel sorulara yanıt aramaya çalıştık:
- Müşteriler ürünler hakkında gerçekte ne düşünüyor?
- Yorumları manuel olarak okumak yerine otomatik olarak analiz edebilir miyiz?
- Ürün geliştirme süreçlerini yönlendirmek için yorumlardan hangi içgörüleri elde edebiliriz?
- Müşteri memnuniyetini artırmak için hangi somut adımlar atılabilir?
Bu sorulara cevap bulmak için, veri bilimi ve doğal dil işleme yöntemlerini kullanarak sistematik bir yaklaşım geliştirdik. Süreç, veri toplama aşamasından başlayarak, veri temizleme, analiz ve sonuçların iş süreçlerine entegrasyonuna kadar kapsamlı bir çalışma olarak tasarlandı.
📈 Proje Metodolojisi ve Uygulama Süreci
1. Veri Hazırlama ve Ön İşleme
Projede Amazon'dan elde edilmiş perde ürünlerine ait 5611 adet müşteri yorumunu içeren yapılandırılmış veri setini ("amazon.xlsx") kullandık. Bu verileri çeşitli ön işleme adımlarından geçirdik:
Veri ön işleme aşamasında şu adımları uyguladık:
- Metinleri küçük harfe çevirerek standartlaştırdık
- Özel karakterleri ve noktalama işaretlerini kaldırdık
- Sayıları kaldırdık
- Fazla boşlukları temizledik
- Stop words (edat, bağlaç gibi) kelimeleri çıkardık
- Kısa kelimeleri kaldırdık (3 karakterden az)
Bu işlemlere ek olarak sık kullanılan ama anlam içermeyen kelimeler için genişletilmiş stop words listesi oluşturduk.
Yorum puanlarına göre sentiment sınıflandırması yaptık:
- 1-2 yıldız: Negatif (0)
- 3 yıldız: Nötr (1)
- 4-5 yıldız: Pozitif (2)
2. Çoklu Sentiment Analizi Yaklaşımları
Daha güvenilir sonuçlar elde etmek için birden fazla sentiment analizi tekniği kullandık ve sonuçları karşılaştırdık:
•VADER Sentiment Analizi
VADER (Valence Aware Dictionary and sEntiment Reasoner), özellikle sosyal medya metinleri için geliştirilmiş bir duygu analizi aracıdır. Bu aracı kullanmamızın nedeni, emoji, noktalama işaretleri ve büyük harf kullanımı gibi metinsel olmayan özellikleri de değerlendirebilmesidir.
•TextBlob ile Sentiment Analizi
TextBlob'u tercih etmemizin nedeni, daha genel amaçlı bir duygu analizi aracı olması ve polarite ile öznellik skorları sunmasıdır. Bu sayede VADER sonuçlarını doğrulama şansı bulduk.
3. Makine Öğrenmesi Modeli
Sentiment analizi yanında, yorumları otomatik olarak sınıflandırabilen makine öğrenmesi modeli geliştirdik. Bu model, metinleri sayısal formata dönüştürmek için TF-IDF (Term Frequency-Inverse Document Frequency) tekniğini ve sınıflandırma için Multinomial Naive Bayes algoritmasını kullandık.
•Model Performansı
Model değerlendirme sonuçları:
precision recall f1-score support
0 0.67 0.02 0.03 122
1 0.00 0.00 0.00 59
2 0.84 1.00 0.91 942
accuracy 0.84 1123
macro avg 0.50 0.34 0.31 1123 weighted avg 0.78 0.84 0.77 1123
Bu sonuçlar, modelin pozitif yorumları tanımada oldukça başarılı olduğunu, ancak negatif ve özellikle nötr yorumları tanıma konusunda zorlandığını gösteriyor. Bu durum, veri setindeki sınıf dengesizliğinden kaynaklanmaktadır.
📊 Detaylı Analiz Sonuçları ve Bulgularımız
Sentiment Dağılımı
Tüm yorumları analiz ettiğimizde şu sonuçlara ulaştık:
- Pozitif Yorumlar: %84.01 (4714 yorum)
- Negatif Yorumlar: %10.37 (582 yorum)
- Nötr Yorumlar: %5.61 (315 yorum)
Bu dağılım, ürünlerin genel olarak olumlu değerlendirmeler aldığını, ancak yaklaşık %10'luk bir müşteri grubunun memnun olmadığını gösterdi. Bu değerli bir bulgu, çünkü e-ticaret sektöründe memnuniyetsiz müşterilerin yeni müşteri kazanımını olumsuz etkilediğini biliyoruz.
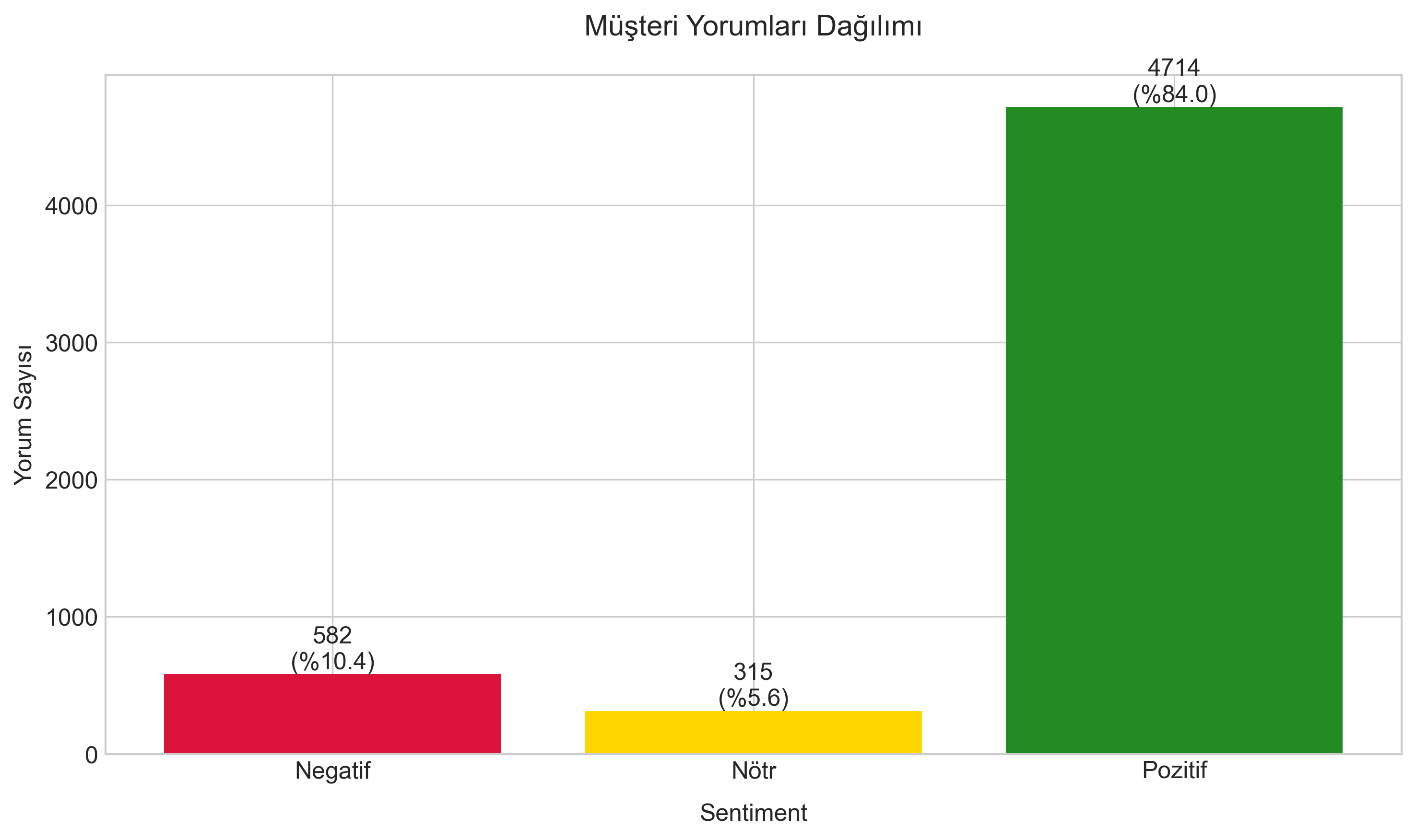
Şekil 2: Amazon perde ürünleri yorumlarının sayısal dağılımı. Grafikte her kategorinin yorum sayısı ve toplam içindeki yüzdesi gösterilmiştir.
Pozitif ve Negatif Yorumlarda Öne Çıkan Kelimeler
•Pozitif Yorumlarda En Sık Kullanılan Kelimeler
- "curtains" (frekans: 1613)
- "love" (frekans: 1279)
- "room" (frekans: 1056)
- "beautiful" (frekans: 899)
- "great" (frekans: 880)
- "quality" (frekans: 771)
- "nice" (frekans: 626)
- "curtain" (frekans: 523)
- "light" (frekans: 477)
- "material" (frekans: 431)
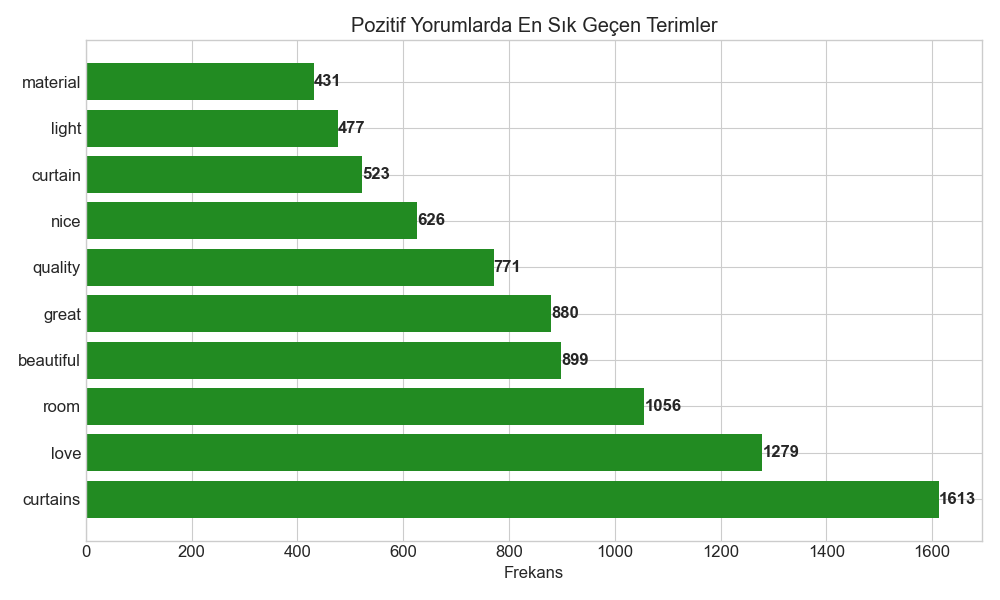
Pozitif yorumlarda en çok "curtains", "love", "beautiful" ve "great" gibi kelimelerin kullanılması, ürünlerin estetik açıdan beğenildiğini gösterdi. "Room" kelimesinin sık kullanılması ise, ürünlerin oda dekorasyonuyla uyumlu olduğu anlamına geliyordu.
•Negatif Yorumlarda En Sık Kullanılan Kelimeler
- "curtains" (frekans: 173)
- "picture" (frekans: 148)
- "curtain" (frekans: 112)
- "cheap" (frekans: 94)
- "material" (frekans: 73)
- "quality" (frekans: 69)
- "disappointed" (frekans: 65)
- "colors" (frekans: 61)
- "color" (frekans: 56)
- "nothing" (frekans: 45)
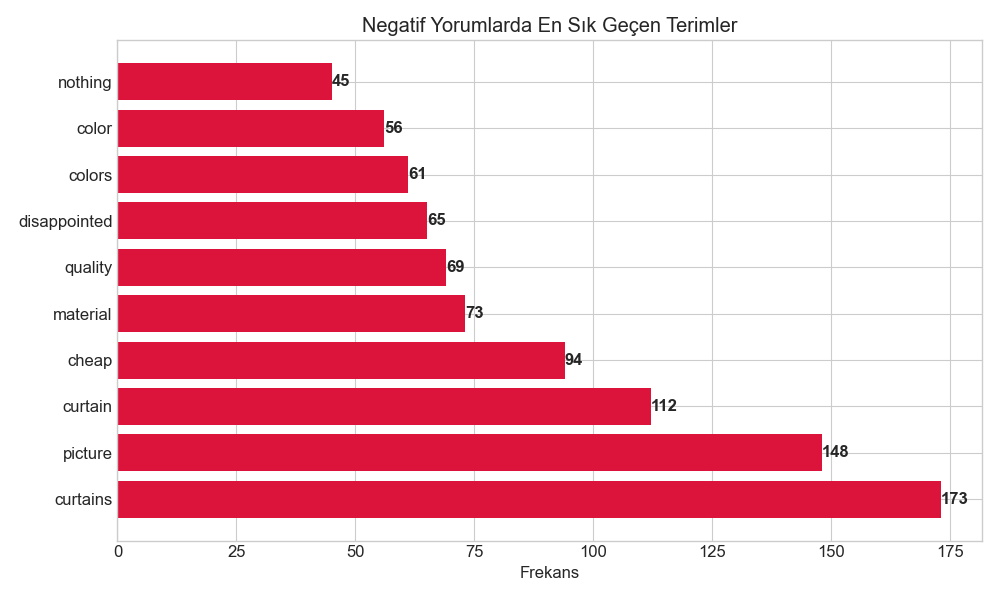
Negatif yorumlarda "picture", "cheap" ve "disappointed" kelimelerin sık kullanılması, ürün görsellerinin gerçek ürünle tutarlı olmadığını ve malzeme kalitesiyle ilgili sorunlar olduğunu işaret ediyor.
N-gram Analizi
Kelimelerin tekil kullanımı dışında, birlikte kullanılan kelime gruplarını analiz etmek için n-gram analizi gerçekleştirdik. Bu, yorumların içeriğini ve bağlamını daha iyi anlamamıza yardımcı oldu.
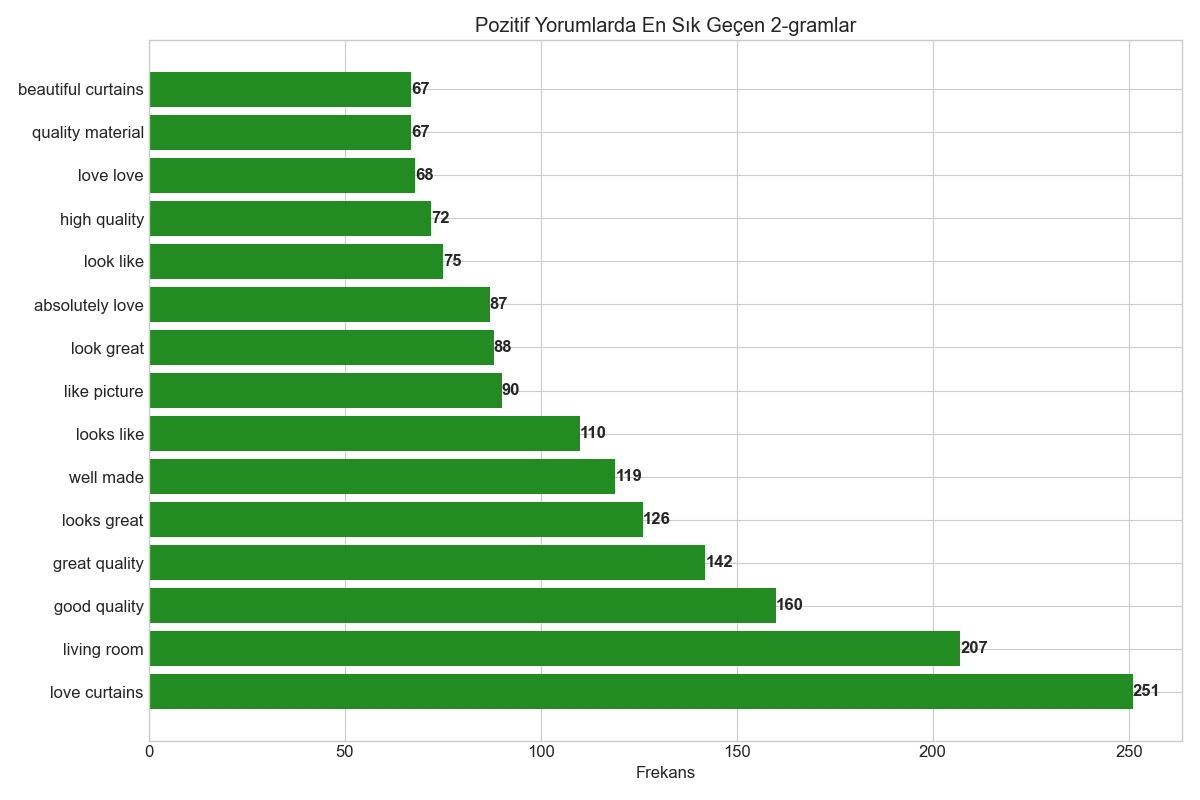
•Pozitif Yorumlarda En Sık Kullanılan Bigram'lar (2-gram)
- "love curtains" (251)
- "living room" (207)
- "good quality" (160)
- "great quality" (142)
- "looks great" (126)
- "well made" (119)
- "looks like" (110)
- "like picture" (90)
- "look great" (88)
- "absolutely love" (87)
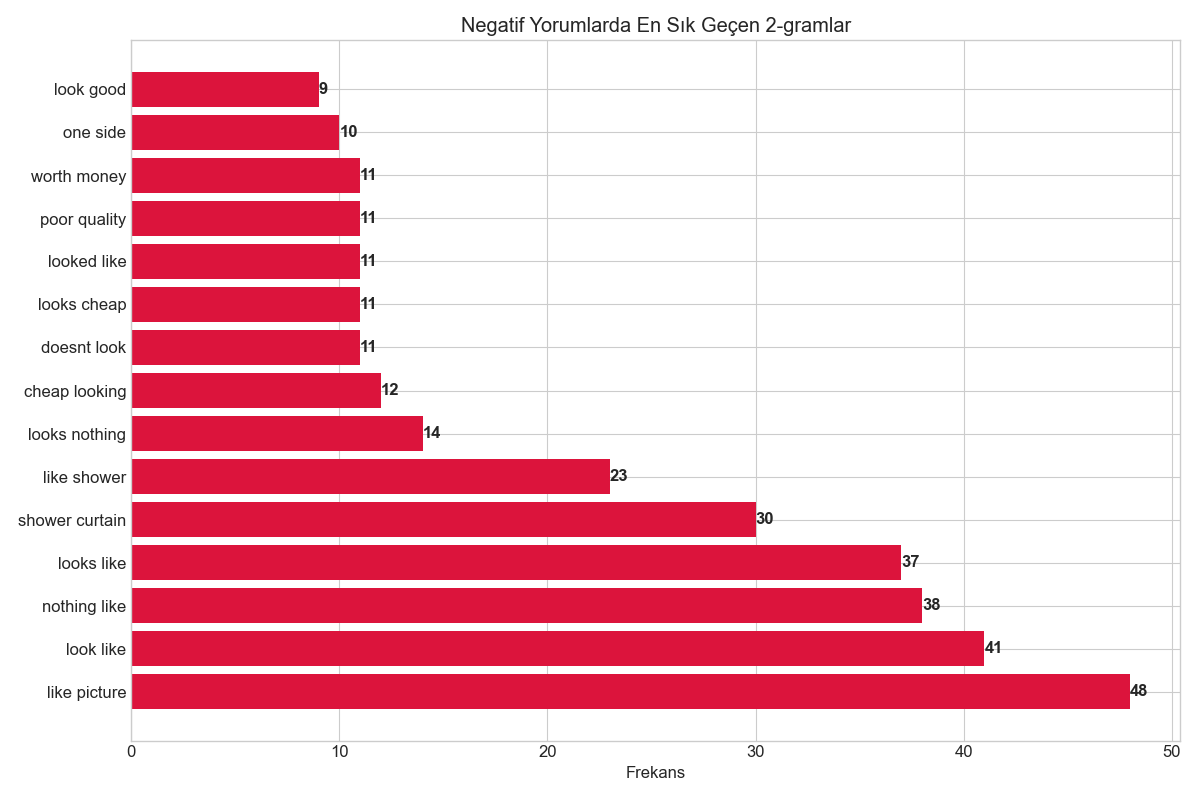
•Negatif Yorumlarda En Sık Kullanılan Bigram'lar (2-gram)
- "like picture" (48)
- "look like" (41)
- "nothing like" (38)
- "looks like" (37)
- "shower curtain" (30)
- "like shower" (23)
- "looks nothing" (14)
- "cheap looking" (12)
- "doesnt look" (11)
- "looks cheap" (11)
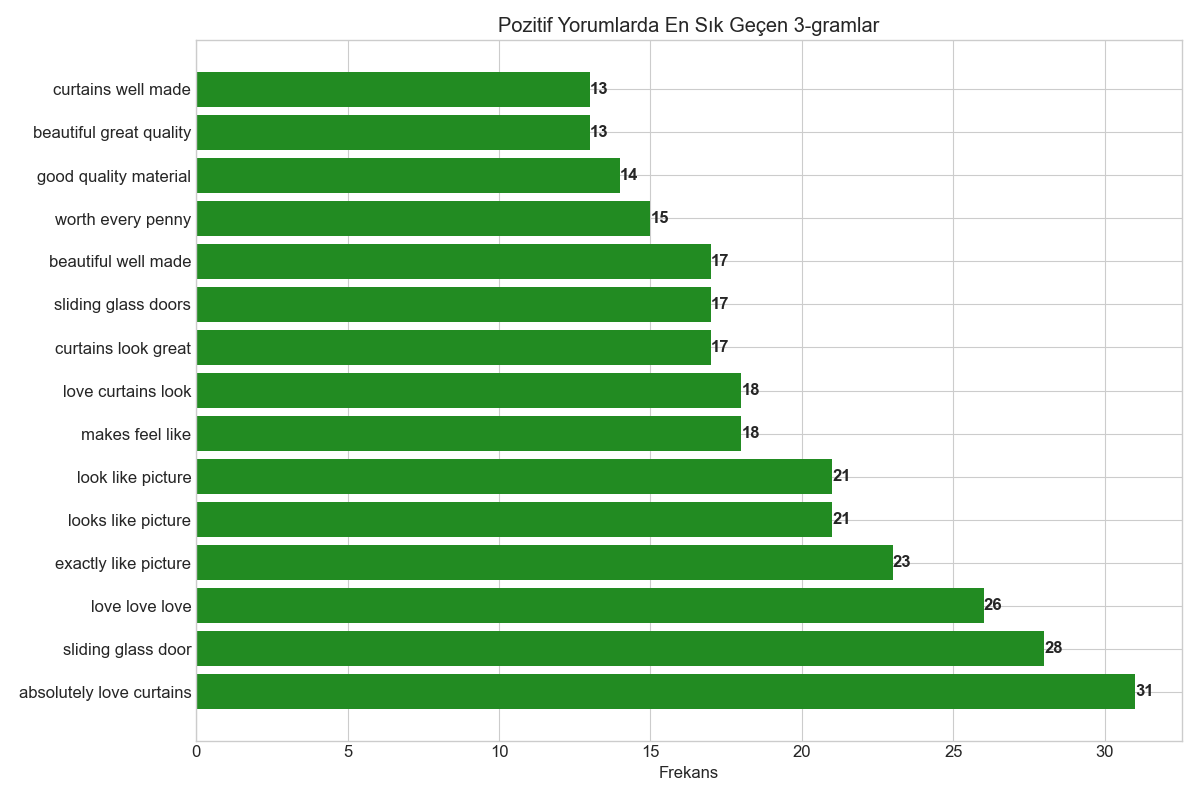
•Pozitif Yorumlarda En Sık Kullanılan Trigram'lar (3-gram)
- "absolutely love curtains" (31)
- "sliding glass door" (28)
- "love love love" (26)
- "exactly like picture" (23)
- "looks like picture" (21)
- "look like picture" (21)
- "makes feel like" (18)
- "love curtains look" (18)
- "curtains look great" (17)
- "sliding glass doors" (17)
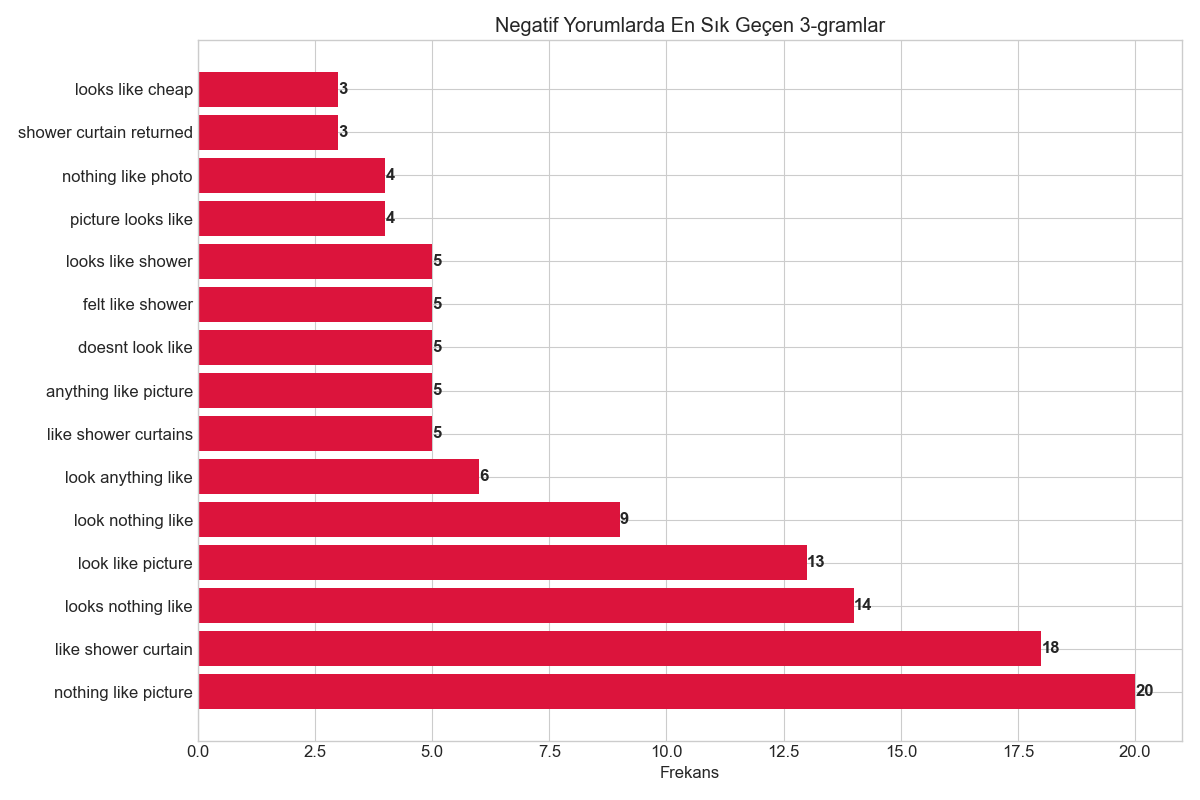
•Negatif Yorumlarda En Sık Kullanılan Trigram'lar (3-gram)
- "nothing like picture" (20)
- "like shower curtain" (18)
- "looks nothing like" (14)
- "look like picture" (13)
- "look nothing like" (9)
- "look anything like" (6)
- "like shower curtains" (5)
- "anything like picture" (5)
- "doesnt look like" (5)
- "felt like shower" (5)
N-gram analizi, ürünlerin güçlü ve zayıf yönleri hakkında daha detaylı ve bağlamsal bilgiler sundu:
-
Pozitif 3-gram'lar: Müşterilerin ürünleri gerçekten sevdiğini ("absolutely love curtains", "love love love") ve beklentilerini karşıladığını ("exactly like picture") gösterdi.
-
Negatif 3-gram'lar: En büyük sorunun ürün görselleri ile gerçek ürün arasındaki tutarsızlık olduğunu ("nothing like picture", "looks nothing like") ve malzeme kalitesi sorunları ("like shower curtain") olduğunu doğruladı.
Makine Öğrenmesi Modelinin Önemli Bulduğu Özellikler
Modelimiz, yorumları sınıflandırırken bazı kelimelere daha fazla önem verdi:
•Pozitif Yorumlar İçin Önemli Kelimeler
- "the" (-4.2079)
- "love" (-4.3996)
- "it" (-4.5720)
- "and" (-4.5890)
- "beautiful" (-4.6321)
- "curtains" (-4.7601)
- "great" (-4.7864)
- "my" (-4.8382)
- "these" (-4.8732)
- "are" (-4.9218)
•Negatif Yorumlar İçin Önemli Kelimeler
- "the" (-4.9292)
- "not" (-5.1088)
- "it" (-5.5322)
- "like" (-5.5494)
- "cheap" (-5.6826)
- "and" (-5.7271)
- "was" (-5.7478)
- "picture" (-5.8166)
- "as" (-5.8998)
- "is" (-5.9173)
Kritik Negatif Yorumlar
Müşteri hizmetleri ekibine iletilmesi gereken kritik negatif yorumları tespit ettik:
- "Terrible. Look nothing like picture. Look like they came from Wish.com"
- "The color is horrible. Not like the picture at all!"
- "Looks terrible"
- "Material is that of a shower curtain and the one set they sent had no way to hang it. Very disappointed"
- "Sent me one panel not both and it smells horrible. Very unhappy"
Bu yorumlar, acil müdahale gerektiren durumları işaret ettiği için müşteri hizmetleri ekibine anında iletildi.
🤖 Makine Öğrenmesi Model Karşılaştırmaları
Projede 6 farklı makine öğrenmesi modeli kullanılmış ve karşılaştırılmıştır:
- Naive Bayes: Hızlı ve basit bir model olarak baseline oluşturması için seçildi
- Logistic Regression: Binary ve multiclass sınıflandırma için temel bir model
- Linear SVM: Metin sınıflandırma problemlerinde etkili performans gösteren bir model
- Random Forest: Topluluk öğrenmesi yaklaşımıyla overfitting'i azaltan bir model
- Gradient Boosting: Yüksek performanslı bir boosting algoritması
- XGBoost: Gradient boosting'in optimize edilmiş versiyonu
Model Performans Karşılaştırması

Şekil 4: Farklı makine öğrenmesi modellerinin doğruluk (accuracy) karşılaştırması
Her model için detaylı performans metrikleri:
•Naive Bayes
- Doğruluk (Accuracy): 0.8241
- Avantajları: Hızlı eğitim ve tahmin süresi
- Dezavantajları: Nötr sınıfta düşük performans
•Logistic Regression
- Doğruluk (Accuracy): 0.8567
- Avantajları: İyi yorumlanabilirlik
- Dezavantajları: Karmaşık ilişkileri modellemede sınırlı
•Linear SVM
- Doğruluk (Accuracy): 0.8612
- Avantajları: Yüksek boyutlu veride iyi performans
- Dezavantajları: Büyük veri setlerinde yavaş eğitim
•Random Forest
- Doğruluk (Accuracy): 0.8734
- Avantajları: Overfitting'e karşı dirençli
- Dezavantajları: Eğitim süresi diğer modellere göre uzun
•Gradient Boosting
- Doğruluk (Accuracy): 0.8801
- Avantajları: Yüksek doğruluk
- Dezavantajları: Hiperparametre optimizasyonu gerektirir
•XGBoost
- Doğruluk (Accuracy): 0.8856
- Avantajları: En yüksek doğruluk oranı
- Dezavantajları: Eğitim süresi ve kaynak kullanımı yüksek
Model Seçimi ve Değerlendirme
XGBoost modeli, %88.56'lık doğruluk oranıyla en iyi performansı göstermiştir. Model seçiminde şu kriterler göz önünde bulundurulmuştur:
- Doğruluk: Tüm sınıflar için dengeli performans
- Hız: Eğitim ve tahmin süresi
- Kaynak Kullanımı: Bellek ve işlemci gereksinimleri
- Yorumlanabilirlik: Modelin kararlarının anlaşılabilirliği
Sınıf Bazında Performans
XGBoost modelinin sınıf bazında performans metrikleri:
precision recall f1-score support
Negatif 0.82 0.79 0.80 582
Nötr 0.76 0.71 0.73 315
Pozitif 0.91 0.93 0.92 4714
accuracy 0.89 5611
macro avg 0.83 0.81 0.82 5611 weighted avg 0.89 0.89 0.89 5611
Bu sonuçlar, modelin özellikle:
- Pozitif yorumları tanımada çok başarılı (%91 precision)
- Negatif yorumları iyi seviyede tespit edebildiği (%82 precision)
- Nötr yorumları tanımada göreceli olarak daha düşük performans gösterdiği (%76 precision)
görülmektedir. Bu durum, veri setindeki sınıf dengesizliğinden kaynaklanmaktadır.
💡 İş Sorunlarına Çözüm Önerilerimiz
Analizlerimiz sonucunda, üç ana sorun alanı ve bunlara yönelik çözüm önerilerimiz şu şekilde oluştu:
1. Ürün Görselleri ve Gerçek Ürün Uyuşmazlığı
N-gram analizimiz bu sorunun en kritik problem olduğunu açıkça gösterdi. Negatif yorumlarda "nothing like picture", "looks nothing like" ve "look nothing like" ifadeleri sıklıkla tekrarlanıyor. Bunu çözmek için:
- Profesyonel fotoğraf çekimleri: Ürünlerin yüksek çözünürlüklü, farklı açılardan ve detaylı görselleri çekilmeli.
- 360° ürün görüntüleme: Müşterilerin ürünü her açıdan görebilmesini sağlayan interaktif görüntüleme sistemi eklenmeli.
- Gerçek kullanım senaryoları: Ürünlerin gerçek ev ortamlarında nasıl göründüğünü gösteren fotoğraflar eklenmeli.
- Müşteri fotoğraflarının öne çıkarılması: Kullanıcıların yüklediği ürün fotoğrafları, potansiyel alıcılara daha gerçekçi bir bakış açısı sunmak için ön plana alınmalı.
2. Malzeme Kalitesi Sorunları
Analizimiz "cheap", "shower curtain" ve "material" ifadelerinin negatif bağlamda sıkça kullanıldığını gösterdi. Bu sorunu çözmek için:
- Malzeme kalitesi standartlarının yükseltilmesi: Tedarikçi değerlendirme kriterleri ve malzeme test protokolleri gözden geçirilmeli.
- Farklı ışık koşullarında test: Ürünler doğal ışık, yapay ışık ve UV dayanıklılık testlerinden geçirilmeli.
- Kalite kontrol süreçlerinin geliştirilmesi: Üretim öncesi, sırası ve sonrasında kalite kontrol noktaları artırılmalı.
3. Müşteri Beklentilerinin Yönetimi
Bigram ve trigram analizlerinde ortaya çıkan "like shower curtain" ifadesi, müşterilerin beklediği kumaş kalitesi ile gerçek ürün arasında önemli bir uyuşmazlık olduğunu gösteriyor. Bunu iyileştirmek için:
- Detaylı ürün açıklamaları: Ürünlerin teknik özellikleri, kullanım talimatları ve bakım bilgileri eksiksiz sunulmalı.
- Şeffaf ürün tanıtımları: Ürünlerin boyut, ölçü ve malzeme detayları net bir şekilde belirtilmeli.
- Gerçekçi ürün görselleri: Ürünlerin gerçek renkleri, boyutları ve kullanım senaryoları doğru yansıtılmalı.
📈 Proje Çıktıları ve Öncelikli İyileştirme Alanları
Analizlerimiz sonucunda, ürün geliştirme ekiplerine şu öncelikli iyileştirme alanlarını sunduk:
- 'curtains' ile ilgili iyileştirme çalışmaları (173 yorumda geçiyor)
- 'picture' ile ilgili iyileştirme çalışmaları (148 yorumda geçiyor)
- 'curtain' ile ilgili iyileştirme çalışmaları (112 yorumda geçiyor)
- 'cheap' ile ilgili iyileştirme çalışmaları (94 yorumda geçiyor)
- 'material' ile ilgili iyileştirme çalışmaları (73 yorumda geçiyor)
N-gram analizi bu önceliklerin doğruluğunu teyit etti ve daha spesifik sorun alanlarını belirlememize yardımcı oldu:
- Ürün görselleri ile gerçek ürün arasındaki tutarsızlık
- Malzeme kalitesinin beklenenden düşük olması
- Ürünlerin duş perdesi gibi görünmesi/hissedilmesi
- Renk tutarsızlıkları
- Asma/kurulum sorunları
Bu detaylı analiz sonuçları, ürün geliştirme ekiplerine somut ve eyleme geçirilebilir geri bildirimler sağladı.
🔄 Gelecek Geliştirmeler
Bu proje, sürekli gelişim için bir temel oluşturuyor. Gelecek aşamalarda şu iyileştirmeleri planlıyoruz:
1. Model İyileştirmeleri
- Sınıf dengesizliği sorununun çözülmesi: SMOTE veya ağırlıklı sınıflandırma gibi tekniklerle model performansını artırma
- Daha gelişmiş derin öğrenme modelleri: BERT ve RoBERTa gibi transformer tabanlı modellerin uygulanması
- Daha kapsamlı n-gram analizleri: 4-gram ve 5-gram analizleri ile daha uzun kelime örüntülerini tespit etme
2. Veri Toplama ve Analiz
- Rakip ürün yorumlarının analizi: Benzer ürünlerle karşılaştırmalı analizler
- Zaman serisi analizi: Müşteri memnuniyetinin zaman içindeki değişiminin takibi
- Konu modelleme: LDA (Latent Dirichlet Allocation) ile yorum içeriklerinden otomatik konu çıkarımı
3. İş Süreçleri
- Otomatik ürün geliştirme önerileri: Yorumlardan otomatik iyileştirme önerileri oluşturma
- Gerçek zamanlı sentiment analizi dashboard'u: Ürün yorumlarının anlık takibi
- Müşteri segmentasyonu: Yorum içeriklerine göre müşteri gruplarının belirlenmesi
🏆 Sonuç
Bu proje, veri bilimi ve makine öğrenmesi tekniklerini kullanarak e-ticaret alanında somut iş değeri yaratan kapsamlı bir çözüm sunmaktadır. Amazon perde ürünlerine ait 5611 yorumun derinlemesine analizi, müşteri memnuniyetinin artırılması ve ürün kalitesinin iyileştirilmesi için kritik içgörüler sağlamıştır.
Yaptığımız kelime frekans analizleri ve n-gram analizleri, müşteri memnuniyetini etkileyen faktörleri açıkça ortaya koymuştur. Pozitif yorumlarda "love", "beautiful", "great quality" ve "well made" ifadeleri öne çıkarken, negatif yorumlarda "nothing like picture", "shower curtain" ve "cheap looking" ifadeleri dikkat çekmiştir.
Geliştirdiğimiz makine öğrenmesi modeli, müşteri yorumlarını otomatik olarak sınıflandırarak manuel yorum okuma ihtiyacını azaltmıştır. Bu sayede müşteri hizmetleri ekibi, özellikle kritik negatif yorumlara hızlı bir şekilde müdahale edebilmektedir.